
Last week, we presented
a new paper that describes how children are thinking through some of the implications of new forms of data collection and analysis. The presentation was given at the
ACM CHI conference in Denver last week and the paper
is open access and online.
Over the last couple years, we ve worked on a large project to support children in
doing and not just learning about data science. We built a system,
Scratch Community Blocks, that allows the 18 million users of the
Scratch online community to write their own computer programs in Scratch of course to analyze data about their own learning and social interactions. An example of one of those programs to find how many of one s follower in Scratch are not from the United States is shown below.
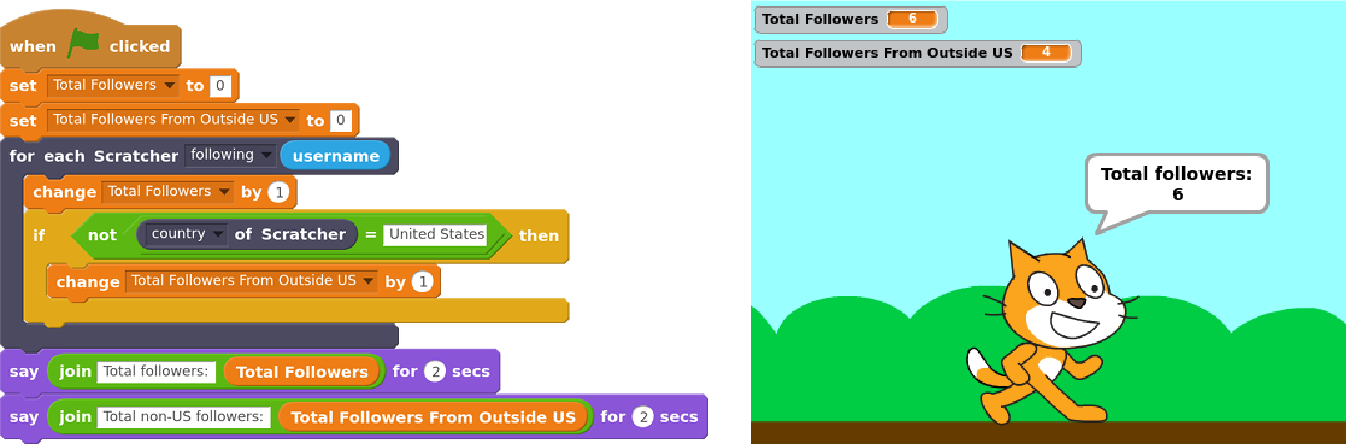
Last year, we deployed Scratch Community Blocks to 2,500 active Scratch users who, over a period of several months, used the system to create more than 1,600 projects.
As children used the system, Samantha Hautea, a student in UW s
Communication Leadership program, led a group of us in an
online ethnography. We visited the projects children were creating and sharing. We followed the forums where users discussed the blocks. We read comment threads left on projects. We combined Samantha s detailed field notes with the text of comments and forum posts, with ethnographic interviews of several users, and with notes from two in-person workshops. We used a technique called
grounded theory to analyze these data.
What we found surprised us. We expected children to reflect on being challenged by and hopefully overcoming the technical parts of doing data science. Although we certainly saw this happen, what emerged much more strongly from our analysis was detailed discussion among children about the
social implications of data collection and analysis.
In our analysis, we grouped children s comments into five major themes that represented what we called critical data literacies. These literacies reflect things that children felt were important implications of social media data collection and analysis.
First, children reflected on the way that programmatic access to data even data that was technically public introduced privacy concerns. One user described the ability to analyze data as, creepy , but at the same time, very cool. Children expressed concern that programmatic access to data could lead to stalking and suggested that the system should ask for permission.
Second, children recognized that data analysis requires skepticism and interpretation. For example, Scratch Community Blocks introduced a bug where the block that returned data about followers included users with disabled accounts. One user, in an interview described to us how he managed to figure out the inconsistency:
At one point the follower blocks, it said I have slightly more followers than I do. And, that was kind of confusing when I was trying to make the project. [ ] I pulled up a second [browser] tab and compared the [data from Scratch Community Blocks and the data in my profile].
Third, children discussed the hidden assumptions and decisions that drive the construction of metrics. For example, the number of views received for each project in Scratch is counted using an algorithm that tries to minimize the impact of gaming the system (similar to, for example, Youtube). As children started to build programs with data, they started to uncover and speculate about the decisions behind metrics. For example, they guessed that the view count might only include unique views and that view counts may include users who do not have accounts on the website.
Fourth, children building projects with Scratch Community Blocks realized that an algorithm driven by social data may cause certain users to be excluded. For example, a 13-year-old expressed concern that the system could be used to exclude users with few social connections saying:
I love these new Scratch Blocks! However I did notice that they could be used to exclude new Scratchers or Scratchers with not a lot of followers by using a code: like this:
when flag clicked
if then user s followers < 300
stop all.
I do not think this a big problem as it would be easy to remove this code but I did just want to bring this to your attention in case this not what you would want the blocks to be used for.
Fifth, children were concerned about the possibility that measurement might distort the Scratch community s values. While giving feedback on the new system, a user expressed concern that by making it easier to measure and compare followers, the system could elevate popularity over creativity, collaboration, and respect as a marker of success in Scratch.
I think this was a great idea! I am just a bit worried that people will make these projects and take it the wrong way, saying that followers are the most important thing in on Scratch.
Kids conversations around Scratch Community Blocks are good news for educators who are starting to think about how to engage young learners in thinking critically about the implications of data. Although no kid using Scratch Community Blocks discussed each of the five literacies described above, the themes reflect starting points for educators designing ways to engage kids in thinking critically about data.
Our work shows that if children are given opportunities to actively engage and build with social and behavioral data, they might not only learn how to do data analysis, but also reflect on its implications.
This blog-post and the work that it describes is a collaborative project by
Samantha Hautea,
Sayamindu Dasgupta, and
Benjamin Mako Hill. We have also received support and feedback from members of the Scratch team at MIT (especially Mitch Resnick and Natalie Rusk), as well as from Hal Abelson from MIT CSAIL. Financial support came from the US National Science Foundation.


 The
The  Since some time we're using siphash algorithm to speed up looking up strings in
Since some time we're using siphash algorithm to speed up looking up strings in 

 Start screen for the Wikipedia Adventure.
Start screen for the Wikipedia Adventure. The number of active, registered editors ( 5 edits per month) to Wikipedia over time. From
The number of active, registered editors ( 5 edits per month) to Wikipedia over time. From  Survey responses about how users felt about TWA.
Survey responses about how users felt about TWA. Survey responses about what users learned through TWA.
Survey responses about what users learned through TWA.
 But the most important part for me was where users want to see improvements. This somehow matches my expectation that we really should improve the user interface.
But the most important part for me was where users want to see improvements. This somehow matches my expectation that we really should improve the user interface.
 We have quite a lot features, which are really hidden in the user interface. Also interface for some of the features is far from being intuitive. This all probably comes from the fact that we really don't have anybody experienced with creating user interfaces right now. It's time to find somebody who will help us. In case you are able to help or know somebody who might be interested in helping, please
We have quite a lot features, which are really hidden in the user interface. Also interface for some of the features is far from being intuitive. This all probably comes from the fact that we really don't have anybody experienced with creating user interfaces right now. It's time to find somebody who will help us. In case you are able to help or know somebody who might be interested in helping, please